 Paper
Paper EditVerseBench
EditVerseBench Code
Code Slides
SlidesVideo Editing
We only show a few samples here. For more visualization, click here
Single Input
Multiple Input
Source Video
Reference Image

Edited Video
Source Video
Reference Image

Edited Video
Video Generation
Image Editing & Generation
Before

After

Before

After

Before

After





Methodology
EditVerse is built on two core principles: enabling powerful in-context learning and ensuring maximum flexibility.
(1) Unified Representation for In-Context Learning: We represent all modalities (text, images, and videos) as a unified one-dimensional token sequence. This sequence is fed into the model built on a full self-attention architecture. This approach allows the model to jointly process and align different modalities, leading to enhanced text comprehension and improved editing quality. Most importantly, it facilitates natural knowledge transfer from the data-rich image domain to the data-scarce video domain.
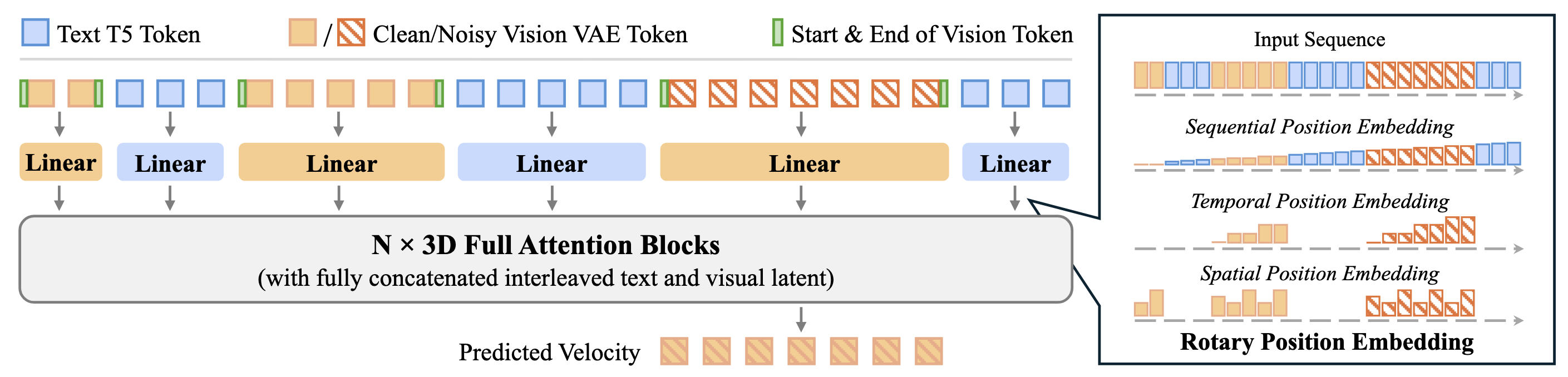 We design a unified framework for image and video editing and generation, which processes text and vision inputs into a unified sequence. The right part of the figure shows our position embedding design. This framework leverages full self-attention to facilitate robust in-context learning and effective knowledge transfer among modalities.
We design a unified framework for image and video editing and generation, which processes text and vision inputs into a unified sequence. The right part of the figure shows our position embedding design. This framework leverages full self-attention to facilitate robust in-context learning and effective knowledge transfer among modalities.
(2) Flexibility via Interleaved Design: Inspired by Multimodal Large Language Models (MLLMs), we use an interleaved design for text, image, and video inputs. This allows EditVerse to process inputs and outputs of arbitrary resolution, duration, and sequential position. To help the model distinguish between these different dimensions, we introduce a novel four-dimensional Rotary Position Embedding (RoPE) that incorporates sequential, temporal, height, and width information.
Quantitative Comparison
| Method | VLM evaluation | Video Quality | Text Alignment | Temporal Consistency | ||
|---|---|---|---|---|---|---|
| Editing Quality ↑ | Pick Score ↑ | Frame ↑ | Video ↑ | CLIP ↑ | DINO ↑ | |
| Attention Manipulation (Training-free) | ||||||
| TokenFlow | 5.26 | 19.73 | 25.57 | 22.70 | 98.36 | 98.09 |
| STDF | 4.41 | 19.45 | 25.24 | 22.26 | 96.04 | 95.22 |
| First-Frame Propagation (w/ End-to-End Training) | ||||||
| Señorita-2M | 6.97 | 19.71 | 26.34 | 23.24 | 98.05 | 97.99 |
| Instruction-Guided (w/ End-to-End Training) | ||||||
| InsV2V | 5.21 | 19.39 | 24.99 | 22.54 | 97.15 | 96.57 |
| Lucy Edit | 5.89 | 19.67 | 26.00 | 23.11 | 98.49 | 98.38 |
| EditVerse (Ours) | 7.65 | 20.07 | 26.73 | 23.93 | 98.56 | 98.42 |
| Closed-Source Commercial Models | ||||||
| Runway Aleph | 7.44 | 20.42 | 27.70 | 24.27 | 98.94 | 98.60 |
Quantitative comparison on EditVerseBench. For open-source research models, we compare two training-free methods (TokenFlow and STDF), one first-frame propagation method (Señorita-2M), and two instruction-guided video editing method (InsV2V and Lucy Edit). Best results are highlighted in bold. We also provide the results of a commercial model, Runway Aleph. While EditVerse lags Runway Aleph in generation quality due to base model differences, our proposed method EditVerse surpasses it in editing faithfulness (via VLM evaluation on editing quality), which is better aligned with human judgment that is further validated by user studies (see paper).
User Study
Citation
If you find our work useful for your research, please consider citing our paper:
@article{ju2025editverse,
title = {EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning},
author = {Xuan Ju and Tianyu Wang and Yuqian Zhou and He Zhang and Qing Liu and Nanxuan Zhao and Zhifei Zhang and Yijun Li and Yuanhao Cai and Shaoteng Liu and Daniil Pakhomov and Zhe Lin and Soo Ye Kim and Qiang Xu},
journal = {arXiv preprint arXiv:2509.20360},
year = {2025},
url = {https://arxiv.org/abs/2509.20360}
}